导入TXT书籍
当你尝试导入一本 TXT 书籍时,应用会要求你进行转换,也就是拆分章节。
为什么要这么做?
我们知道,TXT 是纯文本,不包含任何目录信息,应用不知道该在哪里断章。如果像记事本一样打开 TXT 书籍,一则不便于阅读,二则对于动辄几百万字的网文而言渲染压力太大。
所以阅读助理为了提高阅读体验,要求用户在导入 TXT 时先进行章节拆分。
什么是 自定义正则表达式?
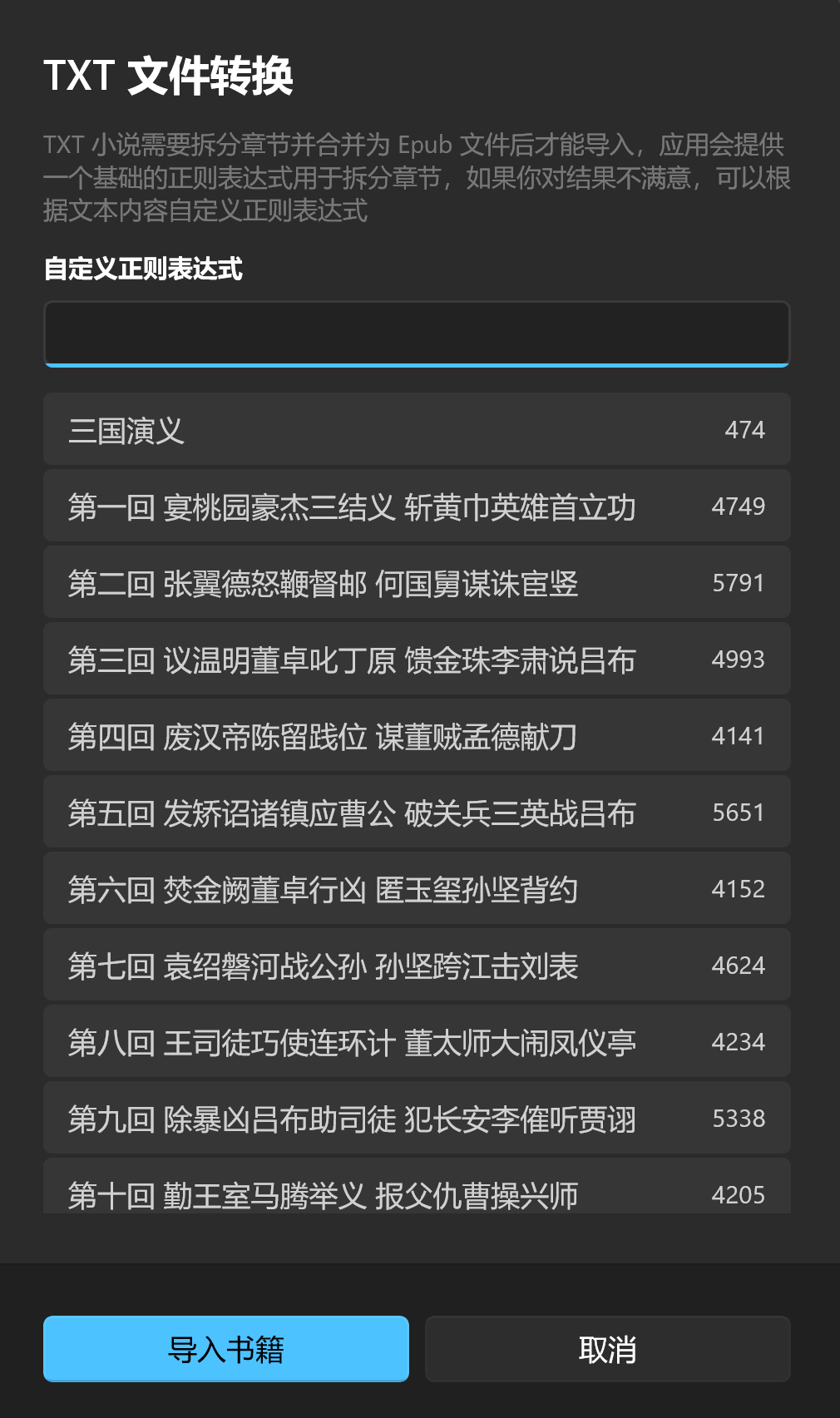
通常来说,一本书的章节名都会保持一个统一的格式,比如 第 xx 章 之类的,应用内置了一个正则表达式:
(第)([―-\-─—壹贰叁肆伍陆柒捌玖一二两三四五六七八九十○零百千O0-90-9]{1,12})([章节節回集卷部篇])
它能够应对绝大多数中文小说的章节拆分(比如上图中的《三国演义》)。
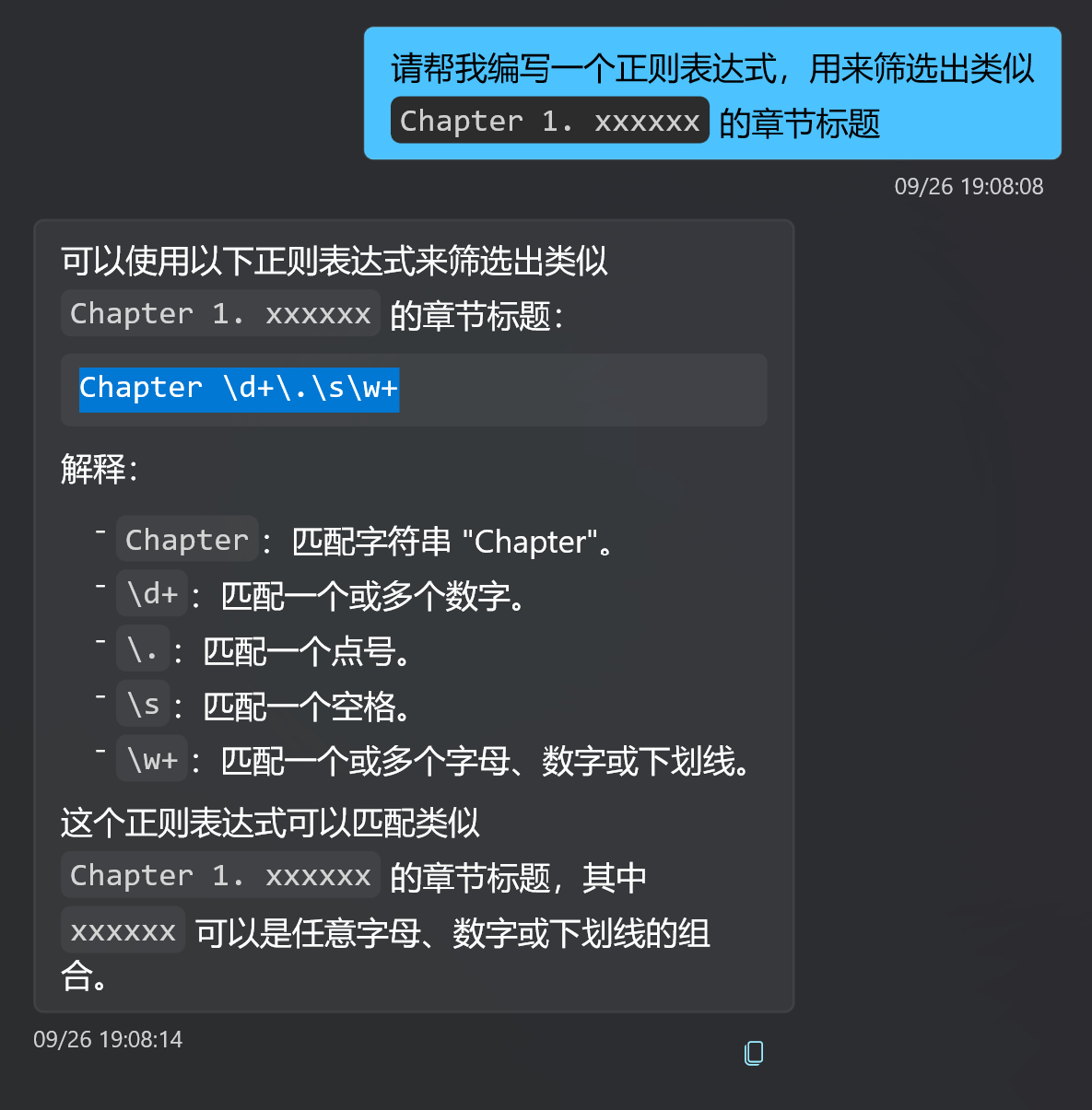
但是总有例外发生,比如你正在读一本英文书籍,章节名类似 Chapter 1. xxxxxx,这个时候,为了更精准地进行章节匹配,你就可以自己写一个简单的正则表达式来对章节进行拆分了。
比如写成 Chapter \d+\.\s\w+
但是正则表达式对于普通用户来说仍需要一些学习成本,在过去,我很难简单地告诉你一个章节匹配的正则表达式该怎么写。不过现在,得益于 ChatGPT 一类的大语言模型横空出世,如果你不清楚某个章节表达式该怎么写,那就询问大语言模型吧!
上面这个 Chapter 表达式,就是我询问 ChatGPT 得到的。
当你得到一个满意的结果后,点击 导入书籍 按钮即可。