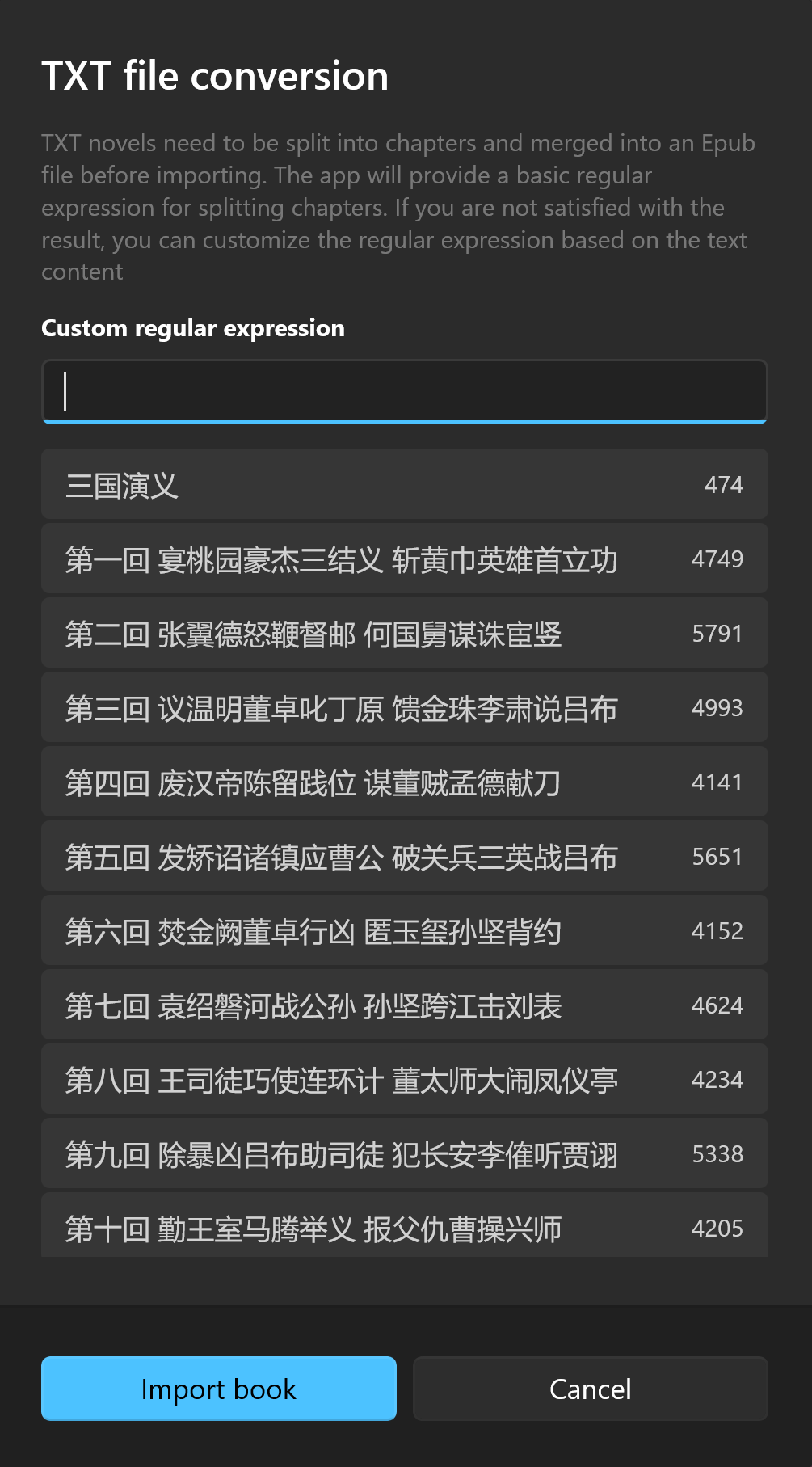
Importing TXT Books
When you try to import a TXT book, the application will ask you to convert it by splitting it into chapters.
Why do we need to do this?
We know that TXT files are plain text and do not contain any directory information. The application doesn't know where to divide the chapters. If we open a TXT book like a notepad, it is not convenient for reading, and it puts too much rendering pressure on web novels that can have millions of words.
Therefore, Reader Copilot requires users to split the chapters before importing TXT books in order to improve the reading experience.
What is "Custom Regular Expression"?
Usually, the chapter titles of a book follow a consistent format, such as "Chapter xx". The application has a built-in regular expression:
(第)([―-\-─—壹贰叁肆伍陆柒捌玖一二两三四五六七八九十○零百千O0-90-9]{1,12})([章节節回集卷部篇])
It can handle the chapter splitting of most Chinese novels (like the one shown in the image above, "Romance of the Three Kingdoms").
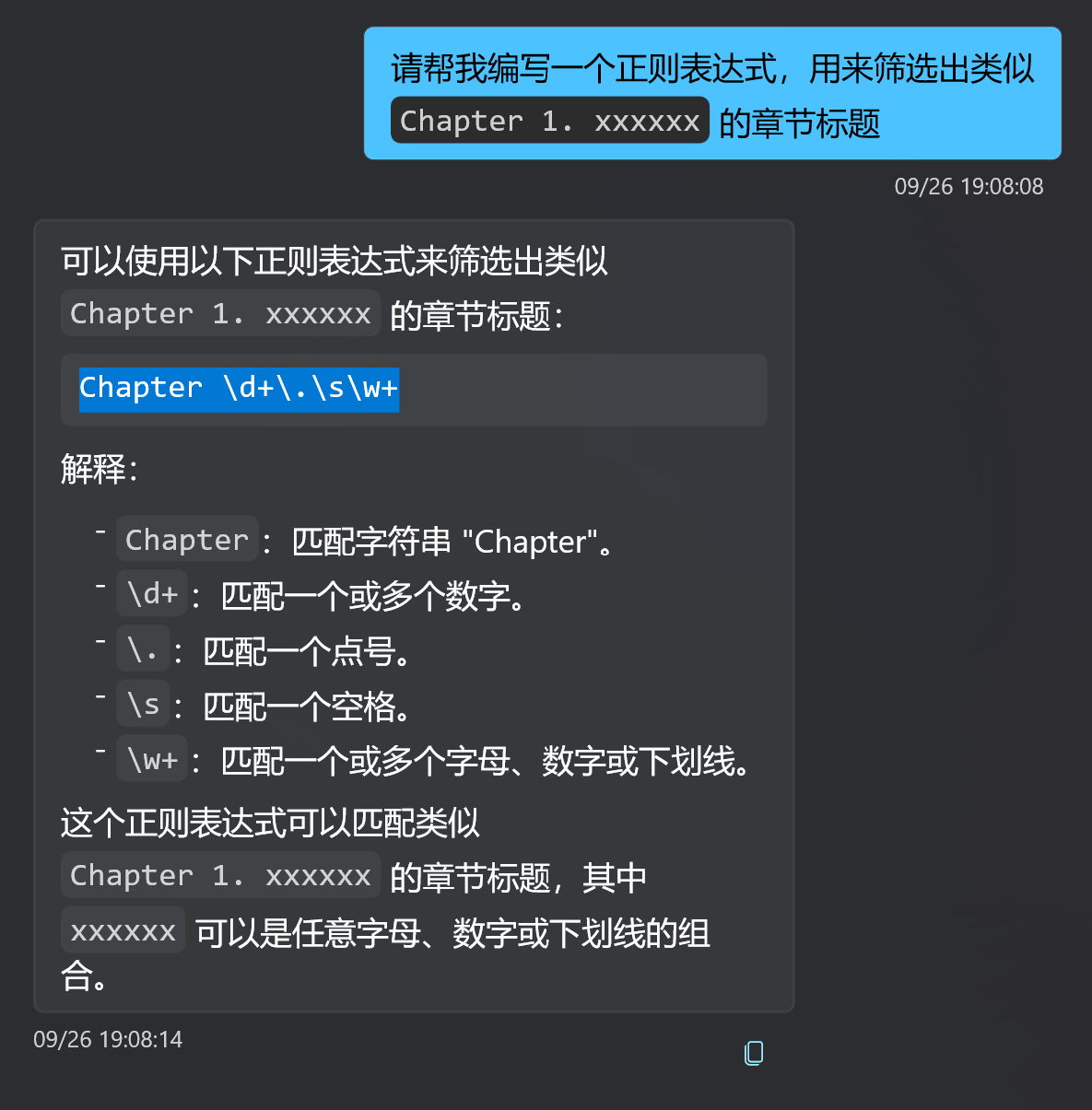
However, there are always exceptions. For example, if you are reading an English book with chapter titles like "Chapter 1. xxxxxx", you can write a simple regular expression to split the chapters more accurately.
For example, you can write it as Chapter \d+\.\s\w+.
But regular expressions still require some learning curve for ordinary users. In the past, it was difficult for me to simply tell you how to write a regular expression for chapter matching. However, now, thanks to the emergence of large language models like ChatGPT, if you are unsure how to write a chapter matching regular expression, you can ask the language model!
The "Chapter" expression mentioned above is what I obtained by asking ChatGPT.
Once you have a satisfactory result, click the "Import Book" button.