AI Support
Currently, the AI support provided by the Reader Assistant includes:
- Semantic search
- Machine translation
- Text-to-speech (TTS)
Semantic Search
Semantic search refers to a knowledge-based question-answering robot built using large language models and vector databases. In the application, it is called "Memory", which means companion reading and secretary.
Typically, when we want to find certain content in a book, we usually use keyword matching. However, this method is relatively inefficient as you still need to process the search results and organize the content yourself.
But with the current popular knowledge base solutions, you can directly ask Shutong questions like What are the features of the smartphones released by Microsoft?
If your document contains semantically related content, the robot will help you extract and organize information to generate an answer.
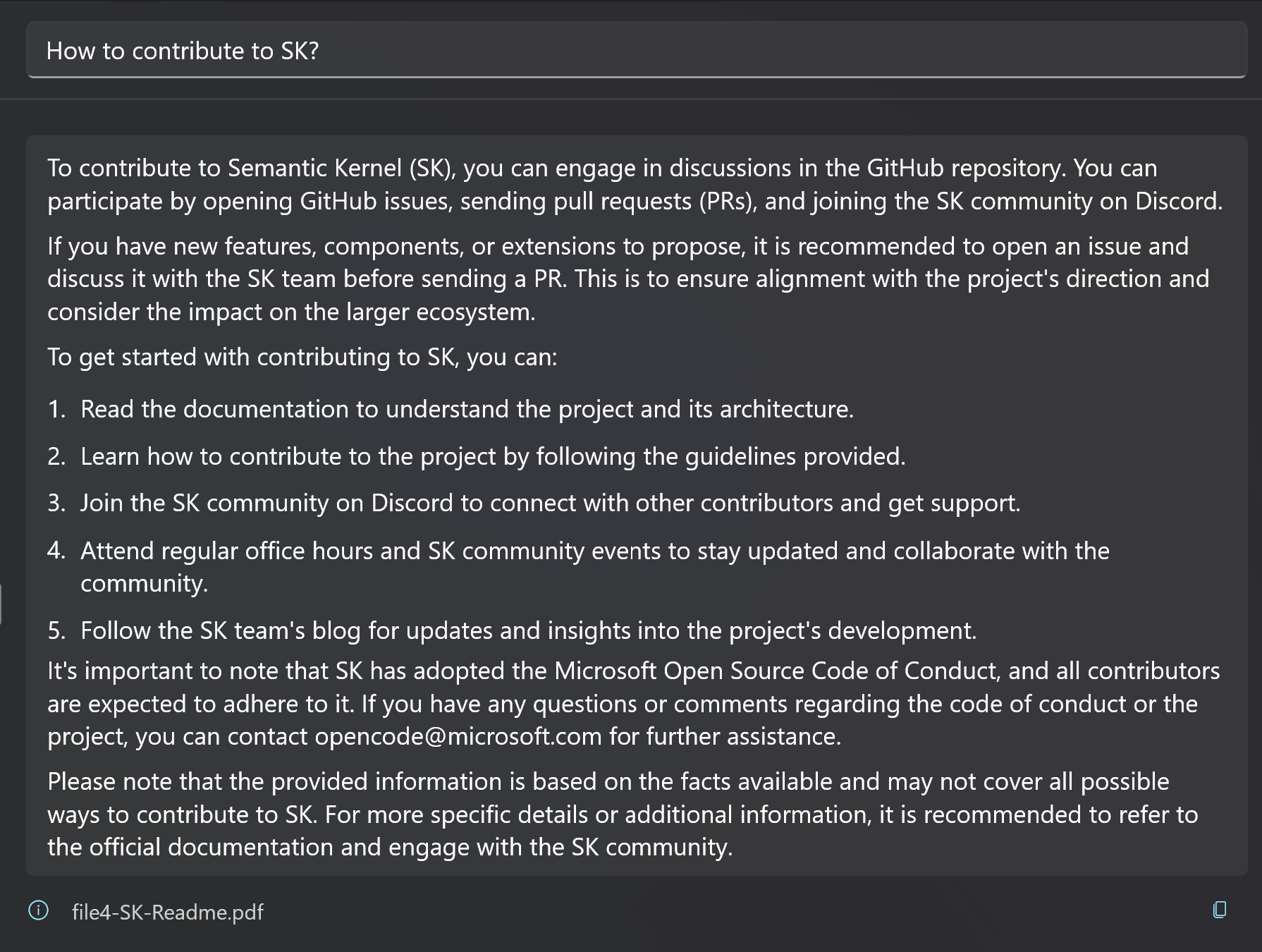
The Memory functionality is divided into two parts: the model part is responsible for text vectorization and text generation, and the storage part is responsible for storing the generated vector information. The following is a detailed introduction of each part.
Model Configuration
The application has two built-in kernels: Azure Open AI and Open AI.
These are two popular AI services, and you need to do some simple configuration by filling in the necessary access keys.
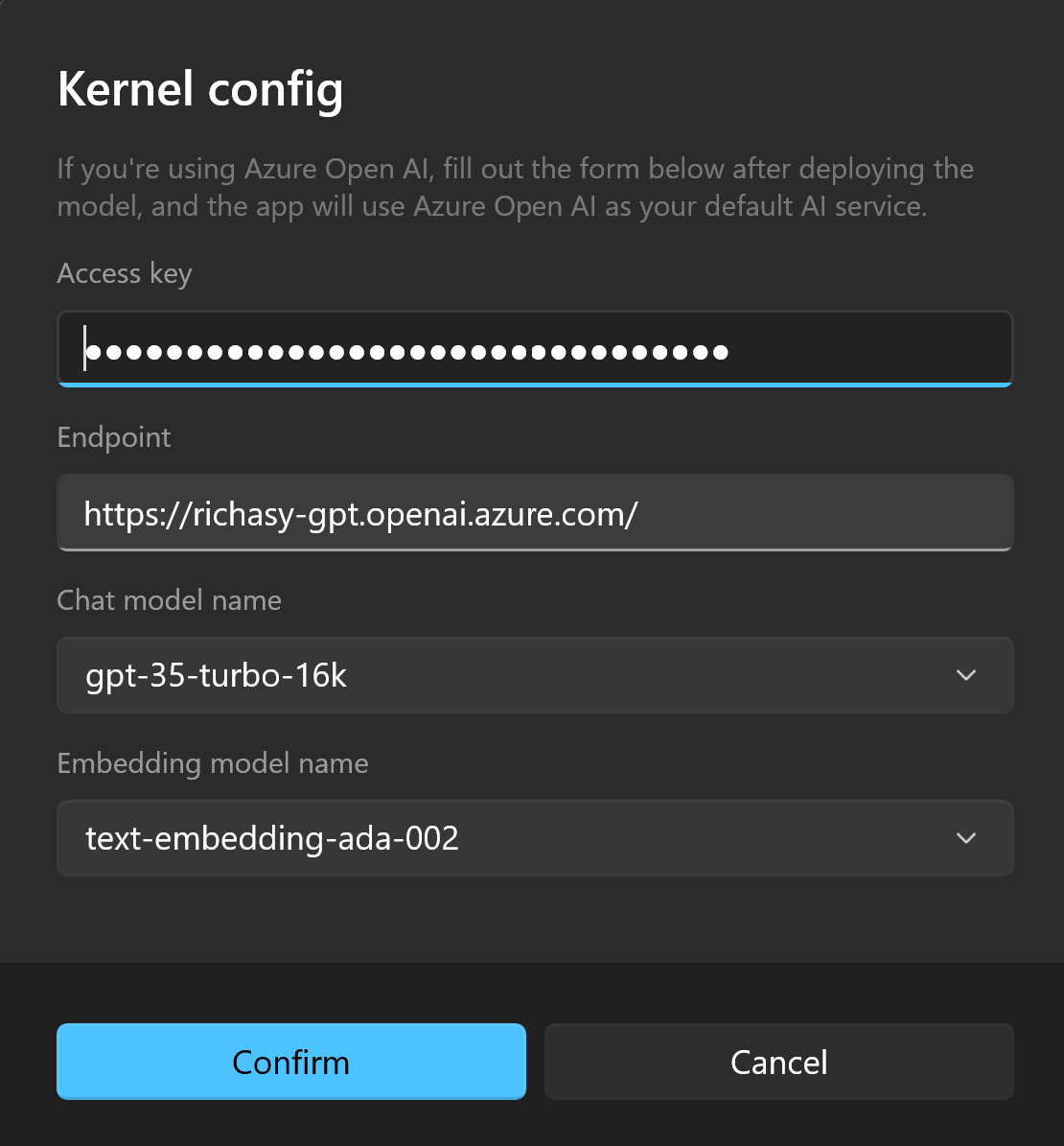
After filling in the relevant information, the application will attempt to retrieve the deployed model list and provide options for selection. Please select the dialogue model and embedding model separately. The recommended combination is: gpt-3.5-turbo and text-embedding-ada-002.
This completes the model configuration.
Extend Models
In addition to the two built-in services, advanced users (who can program) can also extend the service combination by using cutting-edge open-source models and then package them for import into the application.
For information on how to package and example code, please refer to Extend Services.
Configuration Storage
Since the generated content is in vector format, it is best to use a vector database to store the data.
Currently, the application only supports Qdrant database.
This database supports both self-deployment and managed deployment. For users who are new to this, it is recommended to use the official managed platform Qdrant Cloud.
After registration, you can use the free storage repository, which is sufficient for personal use.
Once the deployment is complete, fill in the endpoint and API token in the application configuration.
Basic Usage
Once the configuration is complete, using the Memory is very simple.
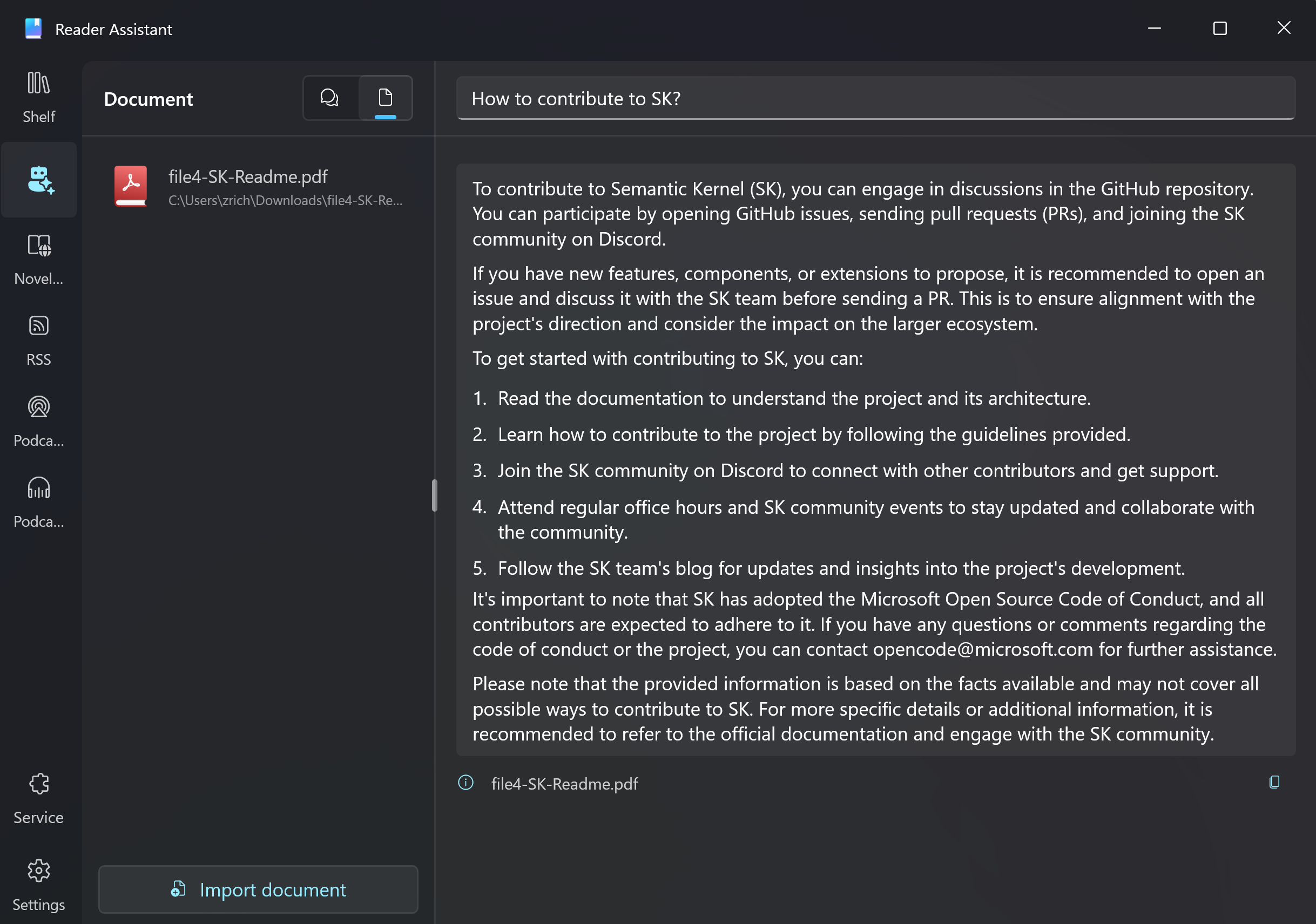
First, on the Memory page, you need to import a document for the first time, and the robot will answer based on that document.
The supported document formats are:
- .txt
- .md
- .doc
- .docx
The application only retrieves the text content inside the document and does not parse image content.
In the interface, you need to enter the question in the top question box and press Enter to query.
Machine Translation
Translation provides two built-in services: Azure Translation and Baidu Translation, which you need to configure in the settings page.
In the Reading Assistant, there are not many language options for translation. You can only translate the text into the current application language.
In most cases, the translation needs while reading are to translate unfamiliar language text into a language I understand, rather than I want to see what this text looks like when translated into another language. Therefore, the translation options provided by the Reading Assistant are only to meet the basic need of being able to understand.
The application provides a feature called "word translation", which is suitable for all text reading scenarios (online books, EPUB, PDF, and RSS).
After selecting the text, right-click or long-press the screen to bring up the text selection menu, where you can find the text translation option. Click on it to translate.
Full Text Translation
The full text translation feature is only available in RSS readers. This feature is designed for quick translation when reading non-native news/articles.
We know that the content of RSS is in HTML format, so translating HTML inevitably includes a bunch of tags. This requires translation services to not translate the content within the tags, otherwise the page will not display correctly.
In this regard, Azure Translator (Bing Translate) does a great job and provides full support for webpage translation.
On the other hand, Baidu Translate is not satisfactory in this area, as stated in its documentation that webpage translation is currently not supported.
如果我需要翻译整个网页,尖括号内的标签无法原样输出,怎么办?
翻译API会将传入的所有字符串当做可翻译字符,目前暂时无法区分哪些部分需原样保留,因此 API 不适合直接处理 HTML 文件。您可将 HTML 文件进行译前处理,抽取出待翻译文本,传入 API 翻译后再回填。
Currently, full-text translation in RSS only supports Azure Translator. If you do not provide the corresponding configuration in the settings, you will not be able to use the full-text translation feature.
To be honest, Azure translation service is really affordable, and it even offers a free monthly quota of one million words. It's like getting something for nothing.
About Text-to-Speech
Windows itself provides an API for text-to-speech, which can be used for free and without limitations. However, the drawback is that the generated speech sounds too robotic, making it torturous to listen to in certain cases.
Therefore, the Reading Assistant does not support local TTS. Instead, it utilizes Azure Speech Services for speech synthesis.
Azure Speech Services provides excellent AI-generated voices. The voice commonly heard in short videos saying "Attention! This man is called Xiaoshuai!" is the Chinese voice named "Yunxi" in Azure.
It also supports local accents such as Henan dialect and Liaoning dialect. In the Chinese-speaking world, Azure Speech Services is the preferred choice for text-to-speech.
Similar to translation, the Reading Assistant provides the feature of reading selected text in all reading scenarios. You can use this feature to learn the pronunciation of certain words.
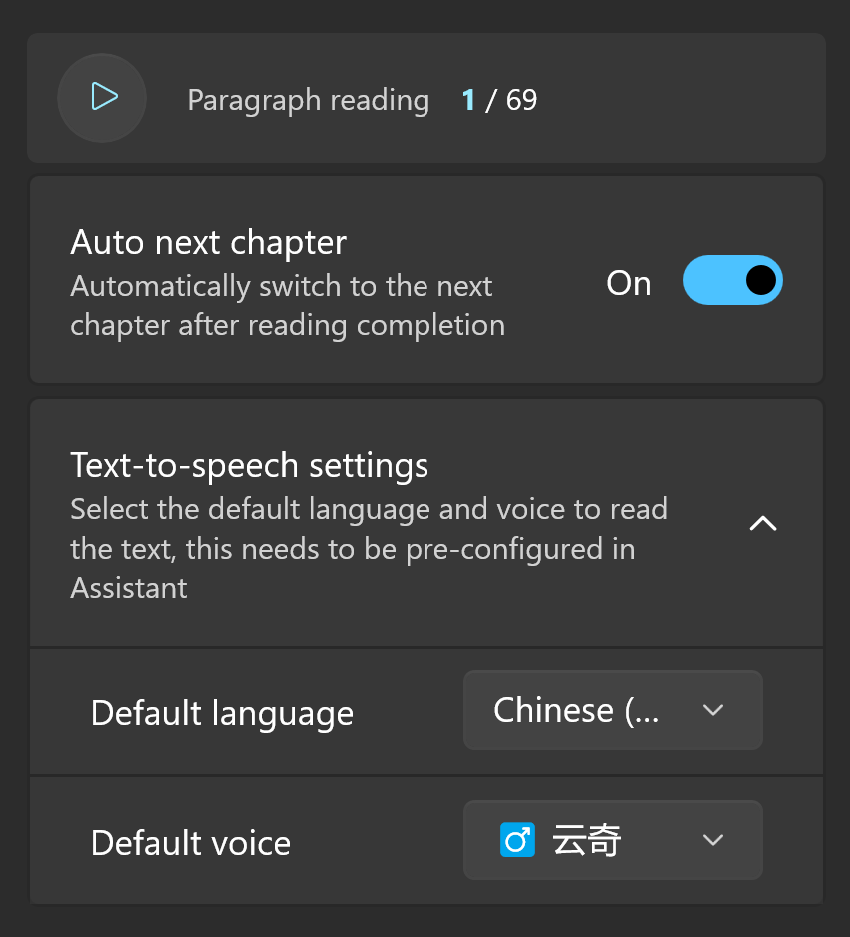
The application provides some settings for TTS, allowing you to adjust the language and voice for speech synthesis in the settings at the top of the reader.
Full Text Reading
Full text reading is currently only available in the online reader, and it provides the function of automatically switching to the next chapter after reading is completed.
In order to reduce the waiting time for speech generation, the application will divide the text into natural paragraphs and generate speech for two paragraphs at a time. One paragraph is used for playback, while the other is prepared. When the first paragraph finishes playing, the next paragraph is seamlessly connected, and speech generation for the next paragraph occurs during playback.
The benefits of this approach are obvious. It not only takes care of the user experience but also reduces costs. If you don't want to listen anymore, you can stop at any time without worrying about wasting the remaining content (at most, one paragraph of speech).